NuLMiLの大きな特徴を4つ、ご紹介します。
(1)少ないデータ数で100%に近い判定精度
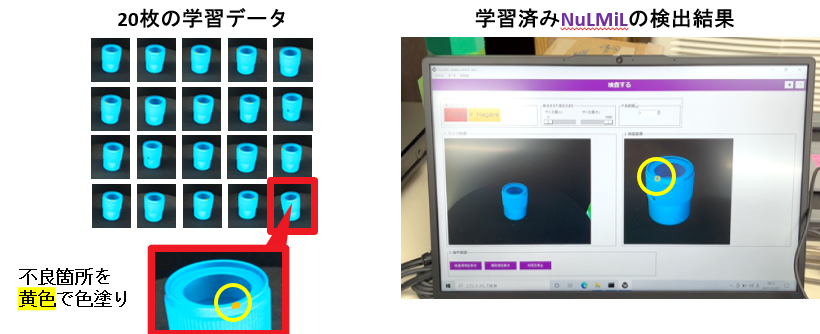
1不良当たり20枚程度と少ないデータ数で100%※に近い精度での不良品判定が可能です。
※下記サンプルでの数値
(2)未知の不良を含めた不良分類が可能
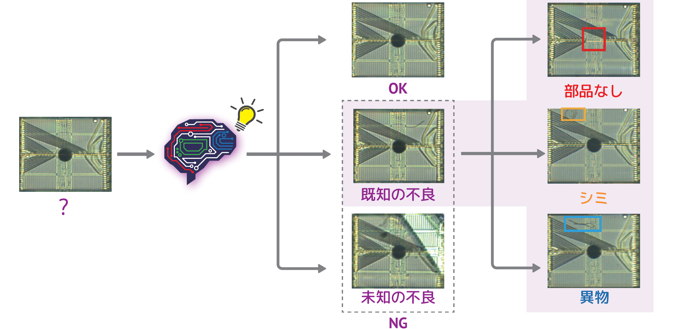
良品学習と不良品学習のハイブリッド学習を採用、製品の良品・不良品の判別だけでなく、不良品の種別分類が可能です。
(3)学習・判定部分で特許取得済み

学習に関する特許:未知の不良を含めた不良分類が可能
推論(判定)に関する特許:少ないデータ数で100%に近い判定精度
(4)色塗りで直感的に学習用データを作成できる

液晶タブレットで不良部分を簡単色塗り、ボタン一つで学習開始
■良品学習と不良品学習についてはこちらで詳しく説明しています








