はじめに:AI検査の概要と利点
AI検査は、ディープラーニングを使った画像解析技術で不良品の検出や品質判定を行う手法です。従来の目視検査では難しかった微細なキズや欠陥も自動で検出でき、24時間稼働が可能な点が大きな強みです。AI検査システムは人が検査できないほど大量の画像を高速に処理できるため、効率的な品質管理を実現します。これにより、人手コストの低減や不良品流出の抑制など長期的なコスト削減効果も期待できます。本記事ではそんなAI検査における、データの質と量の大切さを解説していきます。
伝統的な目視検査との比較
従来の目視検査は、検査員の熟練度や集中力に左右されやすく、作業者の疲労や経験差によるばらつきが避けられません。一方、AI検査は同じ検査条件で長時間連続稼働でき、学習したパターンに基づいて常に一定の精度で判断します。実際、AIは人間が休憩を必要とするのとは異なり24時間体制で動作でき、検査速度と精度を維持します。これにより目視では見逃しがちな小さな欠陥も安定して検出できる点が大きなメリットです。
データ駆動型の技術としての特徴
AI検査は典型的なデータ駆動型技術であり、学習に使う画像データの「質」と「量」が結果を左右します。すなわち、入力データが不十分・不正確な場合には誤った判定結果につながります。よく言われる「Garbage In, Garbage Out(ゴミを入れればゴミが出る)」の原理通り、学習時のデータ品質が悪いとモデルの精度は大きく低下します。このため、AIモデル開発ではデータの準備と整備が最重要課題となり、データ依存性の高さが最大の特徴となります。
PoCの重要性:データで検証する
AI検査の導入では、本格導入の前にPoC(概念実証)を実施してデータ面の検証を行います。PoCでは実際の製品画像でAIモデルを構築し、目標の検出精度が達成できるかを確認します。この段階で「学習データの質と量が十分か」「撮影環境に問題はないか」などをチェックし、データ不足や誤ラベルの有無を早期に洗い出します。こうしたPoCのフィードバックを基に計画を修正することで、導入時のリスクを低減し成功確率を高めることができます。

AI検査における成功要件
AI検査を成功させるには、高品質な学習データの用意・検証、適切な撮影環境の整備、継続的な運用・改善の3点を併せて管理することが不可欠です。特に学習データの品質はAI性能を大きく左右するため、データ収集やラベリング作業は細心の注意を払い徹底する必要があります。また、導入後も実環境で得られた新データでAIモデルを定期更新し続ける運用体制を整えることが、精度維持・向上の鍵となります。
データの質がAI検査に与える影響
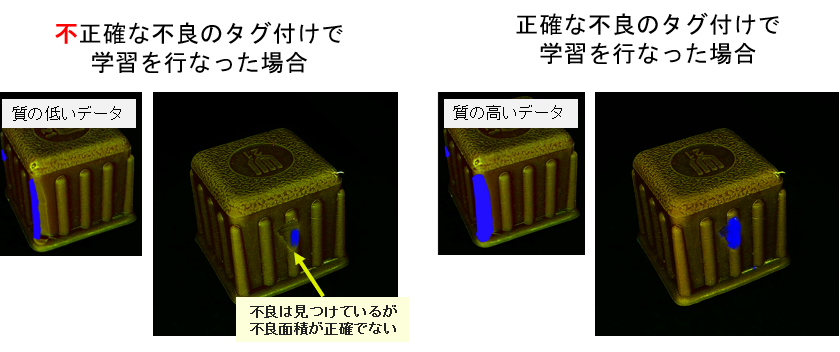
正確なラベリングの必要性
AI検査では、画像データへの正しいラベル付けが何より重要です。例えば、正常品と不良品のサンプルをそれぞれ最低数十枚以上は用意して、1枚1枚に正確な良品/不良品判定ラベルを付与する必要があります。もしラベル誤りや不適切なデータが混入すると、学習したモデルは誤検出を多発し、検出精度が大幅に低下してしまいます。高品質な学習データを準備するため、撮影条件を統一した高解像度画像を用意し、ラベル付け作業に手間と時間をかけることが求められます。
不良品データの不足問題
実際の製造現場では、不良品の発生率が低いことが多く、学習に必要な不良品画像が十分に集まらないケースがあります。さらに、検査員によって何を「不良」と判断するか基準が異なると、データセット内にばらつきが生じ、AI学習の一貫性が損なわれます。このように不良品サンプルの不足と判定基準のぶれは、AI検査の精度安定化における大きな課題です。
撮影環境とデータ品質
検査データの質を上げるには、撮影環境の最適化も欠かせません。具体的には、高解像度カメラや均一な照明によって鮮明な画像を取得し、影や反射、ブレが入り込まないように調整します。例えば、照明を均一に配置し影を抑えつつ被写体を捉えれば、AIは不良箇所をより正確に見分けやすくなります。こうした環境整備は初期投資を要しますが、データ品質向上につながり最終的に検査精度の大幅な改善効果を生みます。
ノイズ・欠損データのクレンジング
収集した画像データにはノイズや欠損が入り込む場合があります。例えば、カメラノイズ、部分的な隠れ、ラベルミスなどが混ざるとAIモデルの学習効率が低下します。そのため、データクレンジング(クリーニング)工程を行い、ノイズ除去や欠損箇所の補完、異常値の排除を実施します。また、画像の向きや解像度などフォーマットを統一し、ラベルの基準を標準化することで、AIが学習に利用しやすいデータに整えます。
継続的なデータメンテナンス
AIモデルは導入後も継続的なデータ更新が必要です。製造環境や製品仕様の変更、新たな欠陥パターンの出現に対応するため、現場で新規取得した画像データを随時追加し、モデルを再学習させます。このように運用しながらデータセットを充実させるサイクルが整備されていれば、AI検査の性能は時間とともに向上し続け、精度劣化のリスクを低減できます。
データの量がAI検査に与える影響

学習に必要なデータ量の目安
AI検査のモデル学習には、大量のデータが求められます。目安として、正常品・不良品それぞれ数十枚以上の画像を最低限用意する必要があると言われます。ただし製品の多様性や欠陥の種類によっては、より多くのサンプルが必要になる場合もあります。一般論として、データ量が増えるほどモデルは多くのパターンを学習できるため、精度向上に寄与します。
データ不足による精度低下
データ量が不十分だとAIモデルは十分に学習できず、精度が頭打ちになる原因となります。特に不良品サンプルが極端に少ない場合、AIは正常品と異常品を識別する学習が不安定になります。海外でも「学習データが不足すると誤った結果を出す可能性が高い」と指摘されており、適切なデータ量確保の難しさがAI導入の課題とされています。
データ拡張と合成データの活用
現実的に十分な実データが集まらない場合には、画像の**データ拡張(オーグメンテーション)**や合成データの活用が有効です。データ拡張では、既存の画像を回転・反転させたり色調を変化させたりして多様なバリエーションを人工的に増やします。また、実在の欠陥データが極端に少ないケースでは、CGやシミュレーションによる合成画像も検討されます。これらの手法で“見た目のバリエーション”を増やし、AIに様々な状況を学習させることで学習サンプル不足を補います。
多様なパターンの学習
学習データには、製品の色や形状、傷の大きさといった多様な特徴が含まれている必要があります。例えば、同じ製品でも異なる角度や背景、照明条件下で複数パターンの画像を用意することで、AIはより一般化された判定力を身につけます。実際、学習データに存在しない新しいパターンが現場に現れると、AIが対応できないリスクがあることが指摘されています。このため、データ量を増やすだけでなく「どのような条件のデータを含めるか」が成功の鍵となります。
過学習回避と量のバランス
ただ単にデータ数を増やせばよいわけではありません。類似の画像ばかりを大量に揃えると、モデルがそのパターンに過度に適応してしまい、別のケースに弱くなる「過学習」が起こる可能性があります。そのため、データ拡張で増やした画像にもバリエーションを持たせたり、集める際に意識的に多様な角度や状態を含めるなど、適切なバランスを考えてデータ収集を行います。結果的には、量とともにバラエティを意識したデータセットづくりが必要です。
製造現場でのデータ収集と課題
現場環境と機器選定(カメラ・照明)
製造現場にAI検査を導入するには、まず撮像環境の整備が重要です。高解像度のカメラや適切なレンズを選定し、製品を鮮明に捉えられるよう配置します。照明もポイントで、均一な明るさになるよう光源を配置し、影や映り込みを極力抑えることで画像品質を向上させます。こうした機器選定と環境設計を行うことで、AIは初めて実物の微妙な不良箇所を正しく学習・検出できるようになります。
検査ラインへの導入の難しさ
既存の生産ラインにAI検査を組み込む際には、工場レイアウトや工程フローとの統合が課題になります。例えば、カメラ設置位置の確保、製品搬送のタイミング調整、ネットワーク環境の整備など、技術的・運用的に検討すべき点が多岐にわたります。海外でも「既存システムとの統合には入念な計画が必要」と指摘されており、専用の計画策定と段階的な導入が求められます。
データ収集体制とラベリング体制
AI学習に使う画像データを安定的に確保するため、収集体制を構築することが重要です。具体的には、生産ライン上にセンサー付きカメラや自動撮影装置を配置し、データ収集システムを導入して運用ルールを定めます。収集した画像は、必ず不良品と良品に分類してフォルダ分けし、機械学習向けの形式に整理します。その後、各画像に対して専門家や教育を受けた担当者がラベリングを行い、モデルが学習できるよう準備します。
工場データの整備:前処理と標準化
製造現場で得られるデータにはばらつきが生じやすいため、前処理によって整える必要があります。具体的には、撮影角度の補正、不要な背景の切り出し、画像サイズの統一などを行い、AIが学習しやすいデータ形状に整形します。さらに、各種データ項目やラベルのフォーマットを標準化することで、異なる工程やラインでも同じ基準でデータを扱えるようにします。これにより、品質の高いデータパイプラインを維持しながらAI検査をスムーズに運用できます。
セキュリティ・プライバシーへの対応
製造データは製品設計図や工程情報など機密性の高い内容を含むことも多く、取り扱いには注意が必要です。データを安全に保管するためにアクセス権限の管理や通信の暗号化、定期的な監査などセキュリティ対策を講じます。また、撮影データに含まれる個人情報(作業者の顔など)があれば、あらかじめ検討・除外するなどプライバシー保護も配慮します。安心してAI検査を運用するには、こうした情報セキュリティの仕組みづくりも不可欠です。
データ品質・量向上のための具体策
データ評価に専門家を巻き込む
AI検査プロジェクトでは、データサイエンティストや画像処理の専門家を早期から参画させ、データ品質の評価・改善を行います。PoCや試験導入では、専門家の視点でモデルの性能とデータ状況を検証し、不足点を洗い出して対策を講じます。特に、PoCの結果から得られたフィードバックをもとに「データの質と量を重視しつつ改善を続ける」アプローチは成功のポイントとされています。
データラベリングの標準化と徹底
学習データの品質はラベリング精度に大きく左右されるため、判定基準やタグ付けルールを明確に定めて統一します。例えば、不良品の種類や重大度をカテゴリー化し、一貫した方法ですべての画像にラベルを付けます。社内教育やドキュメント化によって担当者のばらつきを防ぎ、データセット全体のラベル精度を担保します。このようにラベリングの徹底こそがAI性能最大化に直結する重要な作業です。
データ拡張技術の活用
実データを増やすのが困難な場合は、画像処理技術で疑似的にデータを増量します。具体的には、データオーグメンテーションとして、画像を回転・反転させたり明るさや色調をランダムに変えたりして、学習用のバリエーションを拡大します。こうすることで、限られた不良品サンプルからもより多様な学習パターンを生成でき、モデルの汎用性・頑健性を高められます。データ拡張は、不良検出率向上の有効なテクニックとして広く取り入れられています。
自動化されたデータ収集・更新
可能な限りデータ収集の自動化も進めます。カメラやIoTセンサーを既存ラインに接続して、製品が通過するたびに自動で撮影・保存する仕組みを整備します。これにより、人手によるデータ収集の手間を減らし、時間とともにデータを着実に蓄積できます。さらに、検査結果や新たな異常発見をフィードバックしてデータベースを更新し続けることで、常に最新のデータでAIを再学習させる継続的改善サイクルを構築します。
継続的な評価と改善サイクル
AI検査システムは一度導入したら終わりではありません。生産環境や欠陥のパターンは変化していくため、定期的な性能評価と継続的な改善が欠かせません。具体的には、検査結果のモニタリングを行い、誤検出や見逃しが増えていないかチェックします。問題があれば閾値調整やアルゴリズムの微調整を行い、新しいデータを追加してモデルを再学習させます。このようにAIを取り巻くPDCAサイクルを回すことで、検査精度を常に高い水準に保つことができます。
以上のように、製造業におけるAI検査ではデータの「質」と「量」が成功の要です。品質の高い画像データを十分に収集・整備し、継続的に運用・改善していくことで、AI検査は真価を発揮し、製造業の品質管理・生産性向上に貢献します。